


EPIA: Easily Parallel Instruction Architecture
GitHub: github.com/matrixsmaster/EPIA
A lean, open NPU for on‑device inference and fine‑tuning
Modern robotics is finally demanding serious, private AI at the edge: sub-100 ms reactions, no flaky uplinks, and zero data leaving the robot. The current path - closed GPUs, heavy runtimes, and cloud fallbacks - adds cost, latency, and lock-in. EPIA flips that table: an open, vendor-neutral NPU you can audit, port, and extend. It gives teams independence from Nvidia, deterministic latency under tight power budgets, and a RISC-V–style ecosystem path where anyone can build tools, compilers, and cores without asking permission. That's how we get broad participation, resilient supply chains, and fast iteration for real-world robots.
Why EPIA?
- Built for real edge AI: 64‑bit datapaths, tiny control plane, and a memory system that streams tensors efficiently.
- Simple parallelism: one instruction (
ppu) fans your code into N worker threads; a tiny system controller keeps the cores busy. - First‑class quantization: the Scaled Dot‑Product Unit (SDPU) accelerates per‑block scaled, quantized vectors for modern low‑bit inference.
- No bloat: a tiny, orthogonal ISA with argument width modifiers, and a clean flags model. Easy to hand‑tune; easy to code‑gen.
- Composable: a flexible I/O controller and memory controller make it straightforward to drop EPIA into boards with super-fast DDR, QSPI/Flash, SDIO, and also common low‑speed peripherals.
Typical use case: a full on-robot AI stack
A humanoid ingests sensors continuously: cameras feed a VLM for scene understanding; microphones feed a Whisper-class ASR; the transcript and visual context go to an LLM for reasoning; results branch into multiple streams (gesture/facial control, display/UI, logging), while a large action model plans high-level behavior; finally a fast TTS renders speech. With EPIA, each stage maps cleanly to one NPU "role." Quantized matmuls and attention layers run on the SDPU; the PPU split handles batch/sequence shards; Core0 does the small sequential bits; DMA streams tensors over MINI so compute never starves. Stages that are naturally sequential (e.g., ASR decoding or TTS vocoding) time-slice on a single chip; highly parallel stages (VLM attention blocks, LLM layers, action-model inference) fan out across multiple chips for throughput.
Scaling from lean to blazing
In the minimalist build, one EPIA chip replaces the usual SoC+GPU bundle: Core0 orchestrates, PPU/SDPU crunches quantized kernels, MemC pages weights from DDR/SDIO, and IOC talks directly to body modules over I²C/UART/QSPI - no giant driver stack. In the high-end build, you scatter tasks across several EPIAs: one (or more) for the VLM, one for ASR+TTS, one for the LLM/policy, one for the action planner. You get pipeline parallelism, predictable latency per stage, and full on-robot autonomy - no internet, no data exfiltration, just fast, local intelligence with simple wiring to the rest of the body via IOC.
Architecture at a glance
EPIA is a flexible architecture with theoretically nearly-unlimited amount of cores. The EPIA system can be instantiated with any number of cores which would fit into the target (FPGA or ASIC).
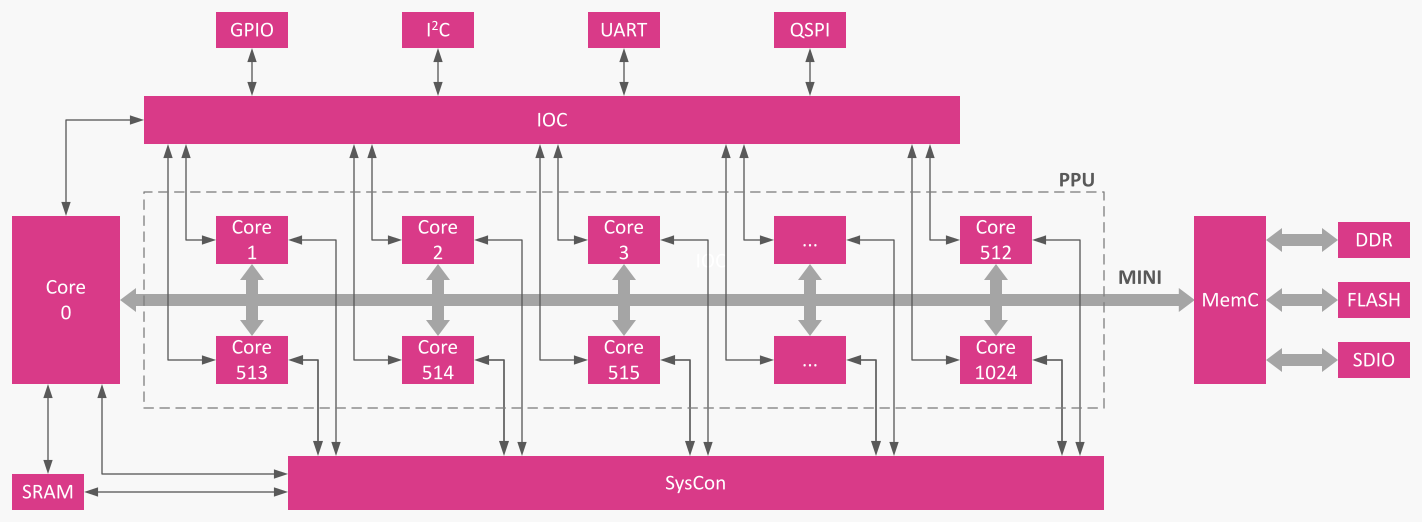
EPIA is organized around a MINI system bus (Memory Interface for Neural Inference). A small System Controller (SysCon) schedules work and arbitrates resources across N+1 identical cores (Core0 plus a Parallel Processing Unit, PPU). A Flexible Memory Controller (MemC) streams to and from DDR/Flash/SDIO, while an I/O Controller (IOC) handles atomic transfers on I²C, UART, QSPI, and so on.
Core0 typically runs the sequential parts of your program, while the PPU cores crush the parallel regions. When a ppu instruction is encountered, execution splits into k threads (you choose k). If there are fewer physical cores than threads, SysCon runs the remainder as soon as a core frees up - no scaffolding required in your code.
Core micro‑architecture
The cores are homogeneous, sharing the same architecture, and consist of the same key elements. Core0 also has the same architecture, just with a slightly longer pipeline.
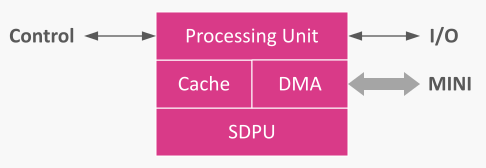
Each core has:
- a Processing Unit that executes the instructions,
- a DMA engine to pull/push tensors over MINI,
- a Cache tuned for streaming tensors and handling thread-local data, and
- the SDPU block for quantized scaled dot‑product math.
The uniform core design keeps scheduling simple and makes performance predictable.
Programming model
EPIA uses a compact, orthogonal ISA with width‑modified mnemonics: append b/h/w/d to operate on 8/16/32/64‑bit data (default is 64‑bit). Example: movb, cmpw, addd. There are integer, float, logic/shift, and control‑flow families, plus I/O and DPU access instructions.
A few small rules make the model both expressive and safe on low‑bit pipelines:
- Explicit width is a feature. You choose how wide each op reads/writes - which is perfect for tightly packed tensors and mixed‑precision flows. Conversions are explicit (
itf,fti), withfti*reading 32‑bit float and writing the integer width you select. (fp16 support coming soon) - All operands are memory‑resident. The hardware cache and DMA make this workable and keep the ISA compact.
- Flags are minimal.
Z/L/G/Egive you predictable branching without hidden surprises.
For parallel code, the clo instruction marks locations as thread‑local clobbers to prevent cross‑thread cache contamination when multiple threads use the same scratch slots (iterators, temporaries, accumulators). The cache makes these accesses blazingly fast, and securely contained for each core.
Parallel execution that fits in your head
EPIA allows for a very easy and intuitive parallelization from the software's point of view.
 {float=none}
{float=none}
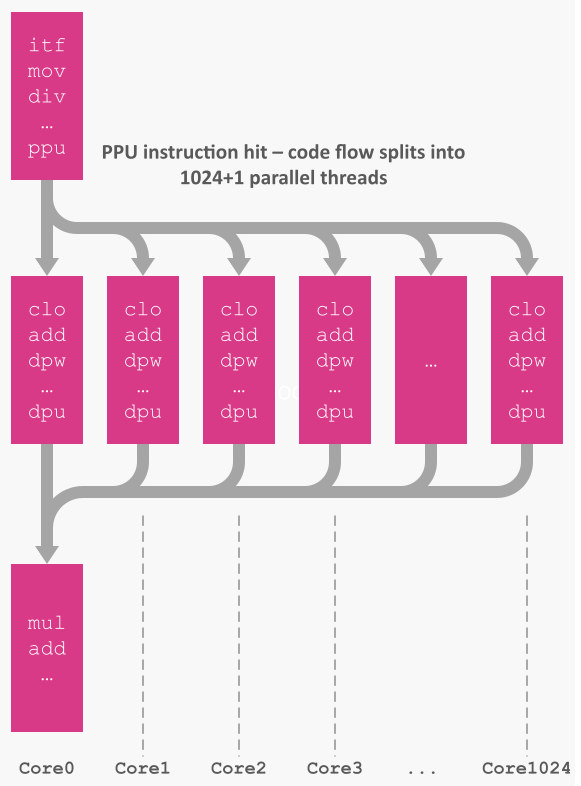
When a ppu instruction triggers, your code literally forks into NThreads slices. Each thread gets a small sequential ID (0..N‑1) written to a memory location you choose, which you can use for striding or block indexing. Threads run until they hit your barrier address (or hlt), then control returns to Core0 at the next instruction after ppu.
This design gives you the benefits of a thread pool - without creating or managing one. If NThreads exceeds available cores, SysCon transparently schedules the overhang. In practice you can just pick a grid/block shape that matches your tensor and let the hardware do the rest.
Note: check out our LLM inference or 3D rendering demos to see how easy it is to program with PPU!
SDPU: quantized math without the pain
Modern inference is quantized. EPIA bakes this in with the Scaled Dot‑Product Unit:
- Per‑block scale handling for common quantized formats.
- Register interface (
dpw/dpr) to set up blocks, formats, and shapes. - Single instruction (
dpu) to kick off the operation and return a single scalar result. - Cache prefetching tuned to stream packed vectors efficiently.
Pair SDPU with PPU fan‑out and you get very high sustained throughput on attention, matmul, and convolution‑like dot‑product kernels.
Memory & I/O
- MINI bus is optimized for tensor streaming and DMA burst transfers.
- MemC abstracts DDR/Flash/SDIO so you can boot, page models, and checkpoint state with ease.
- IOC gives you atomic, ordered I/O on common embedded links (I²C, UART, QSPI) so devices can be commanded or logged in lockstep with compute.
Developer experience
- Small ISA surface you can memorize in an afternoon.
- Width‑suffix discipline lets you pack memory tightly and pick exactly where truncation/extension occurs.
- Deterministic flags and a clear
jmp/jifmodel keep control‑flow obvious. - Thread‑local clobbers (
clo) and a single‑op parallel split (ppu) remove the usual parallel‑programming foot‑guns. - Straight‑line kernels are easy to code‑gen from a compiler or to hand‑tune when you need absolute control.
If you enjoy writing tight kernels - or generating them - EPIA will feel like a friendly, modern descendant of classic vector machines, minus the baggage, plus the performance and scale.
Typical workloads
- LLM/VLM inference on edge, with models of meaningful size (7B+)
- On‑device fine‑tuning with mixed‑precision accumulators
- Signal processing and feature extraction where scaled dot‑products dominate
- Robotics/embedded AI that need deterministic timing and compact binaries, while requiring to process large models
What to expect
EPIA favors predictability and composability over "do‑everything" complexity. That means you get:
- near‑linear scaling on embarrassingly parallel kernels,
- steady throughput on quantized math via SDPU,
- tight control of memory bandwidth, and
- a codebase you can actually understand.
If you value small, sharp tools for real edge AI, EPIA is for you.